What every programmer would like is a private, infinitely large, infinitely fast memory is also nonvolatile. Unfortunately, such memories don’t exist at present. A second choice is memory hierarchy, with cache, main memory and disk storage.
The job of operating system is to abstract this hierachy into a userful model and then manage the abstraction. And this part of the OS is called the **memory manager **.
Memory Management Requirements
There are some requirements that memory management is intened to satisfy:
- Relocation:
- Protection:
- Sharing
- Logical organization
- Physical organization
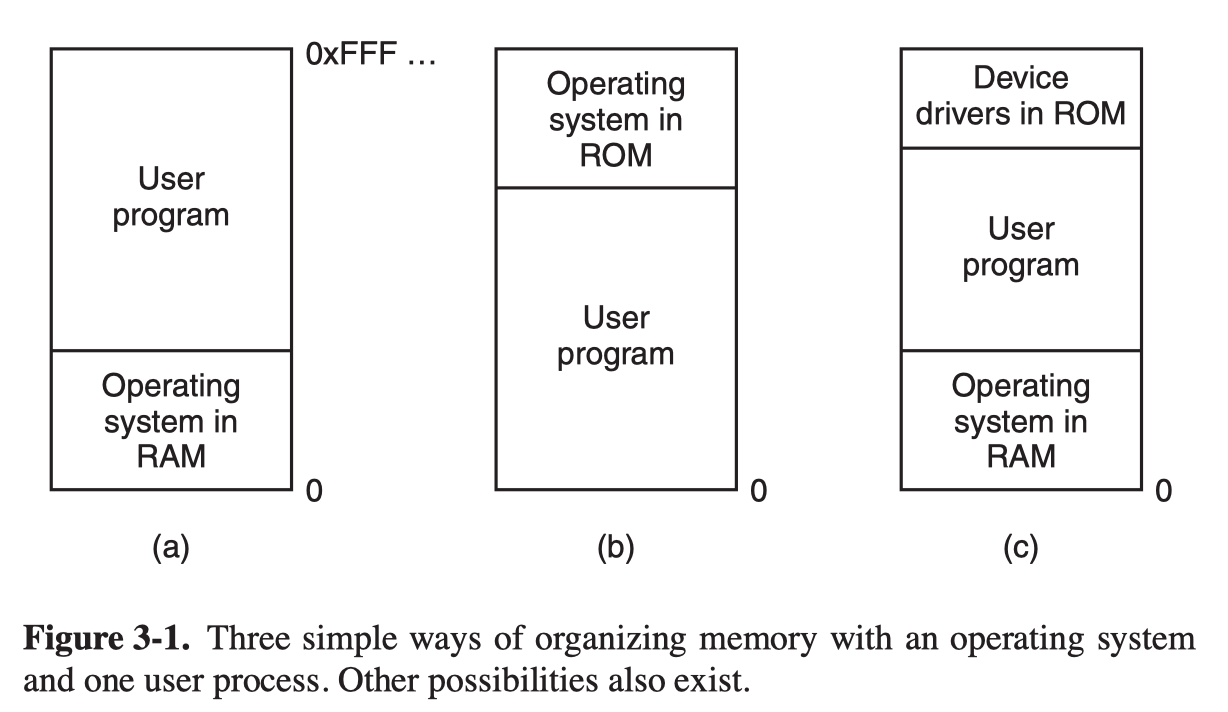
No Memory Abstraction
With the model of memory being just physical memory, generally only one process at a time can be running.
One way to get some parallelism in such a system with no memory abstracion is to program with multiple threads, since all threads in a process are supposed to see the same memory image.
It is also possible to run multiple programs at the same time by swapping, the OS:
- first saves the entire contents of memoey to a disk file
- then brings in and runs the next program
Suppose two programs loaded consecutively into memory, it raises a problem that the two programs both reference absoulte physical memory.
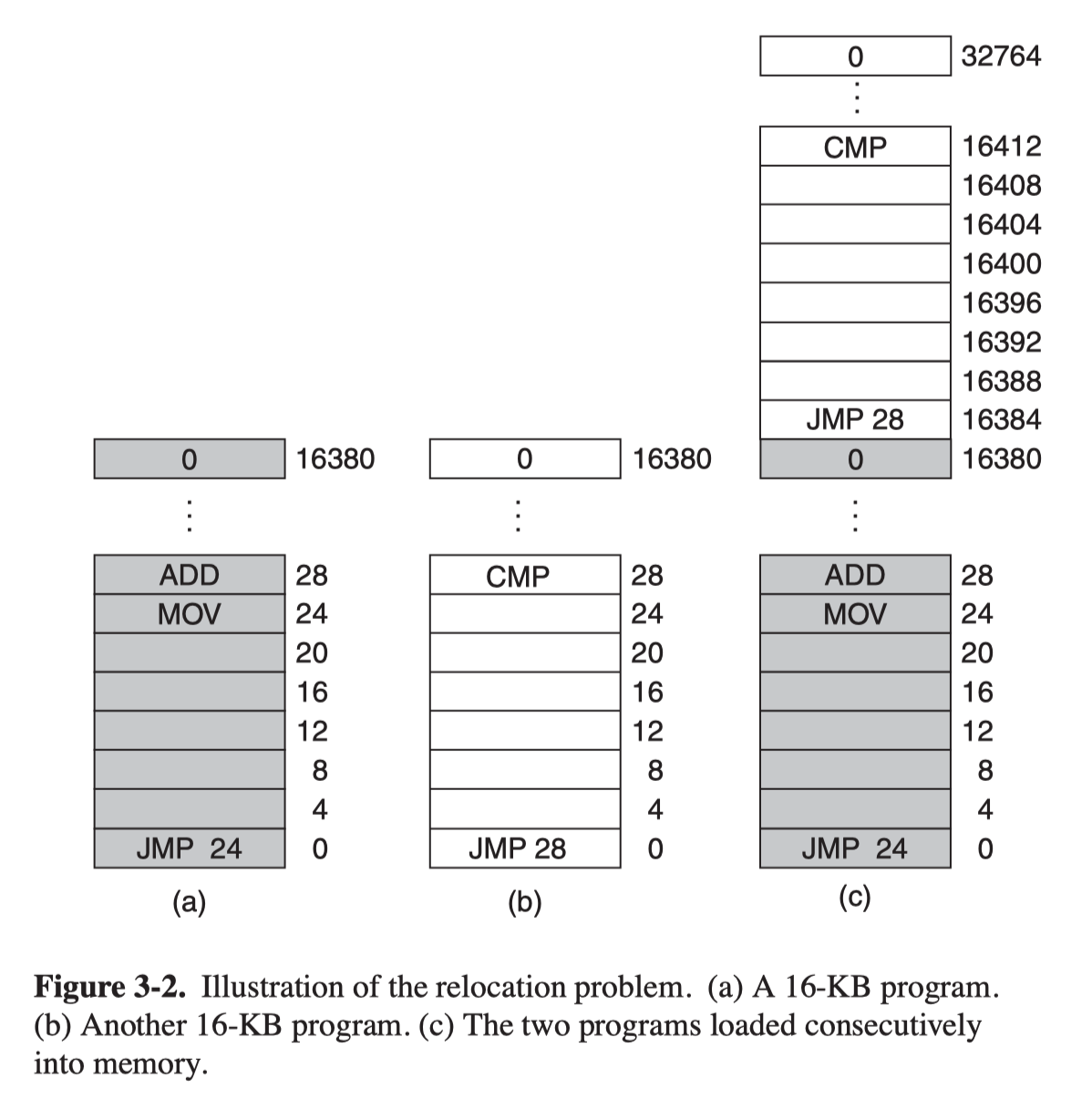
One solution is called static relocation. When a program was loaded, the constant of starting address is added to every program address. However, it’s quite slow, and requires some way to tell what is an address and what is a constant.
Memory Abstraction: Address space
An address space is the set of addresses that a procss can use to address memory. Each process has its own address space, independent of those belonging to other processes.
Base and Limit registers
There is a simple solution to give each program its own address space, with the dynamic relocation technique. It maps each process’s address space onto a different part of physical memory with two special hardware registers:
- Base: the physical address where its program begins in memory
- Limit: the length of the program
Every time a process referent memory:
- CPU automatically adds the base value to the address generated by the process before sending it out on to memory bus
- It also checks whether the address offered is equal to or greater than the value in limit register.
The base and limit registers are protected so that only the operating system can modify them.
A disadvantage is the need to perform an addition and a comparsion on every memory reference.
Swapping
In practice, the total amount of RAM needed by all the processes is oftern much more than can fit in memory. The simplest strategy to dealing with memory overload, called swapping, consists of bringing in each process in its entirety, running it for a while, then putting it back on the disk.
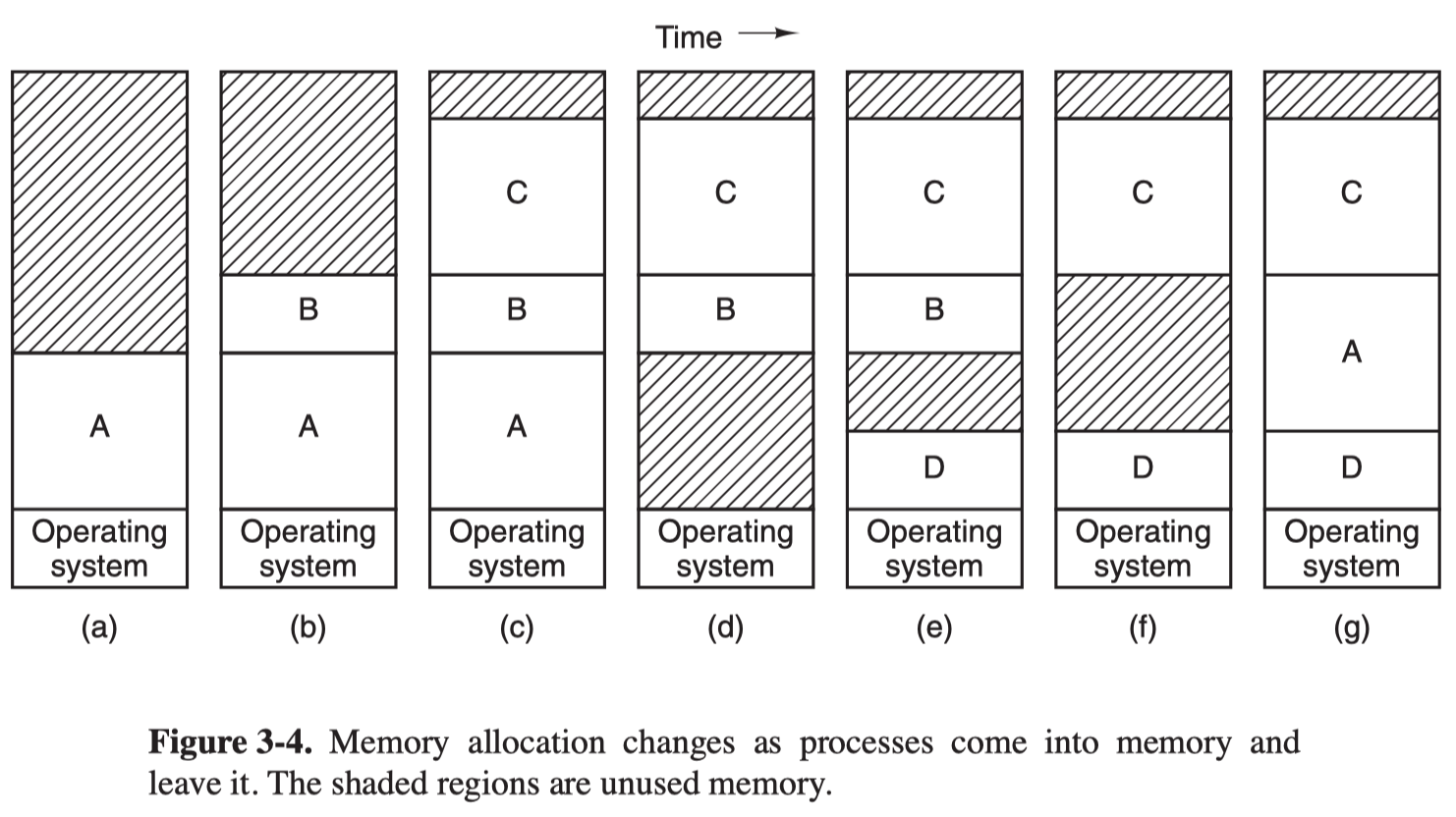
When swapping creates multiple holes in memory, it is possible to combine them all into a big one by moving all the processes downward as far as possible, which is called memory compaction.
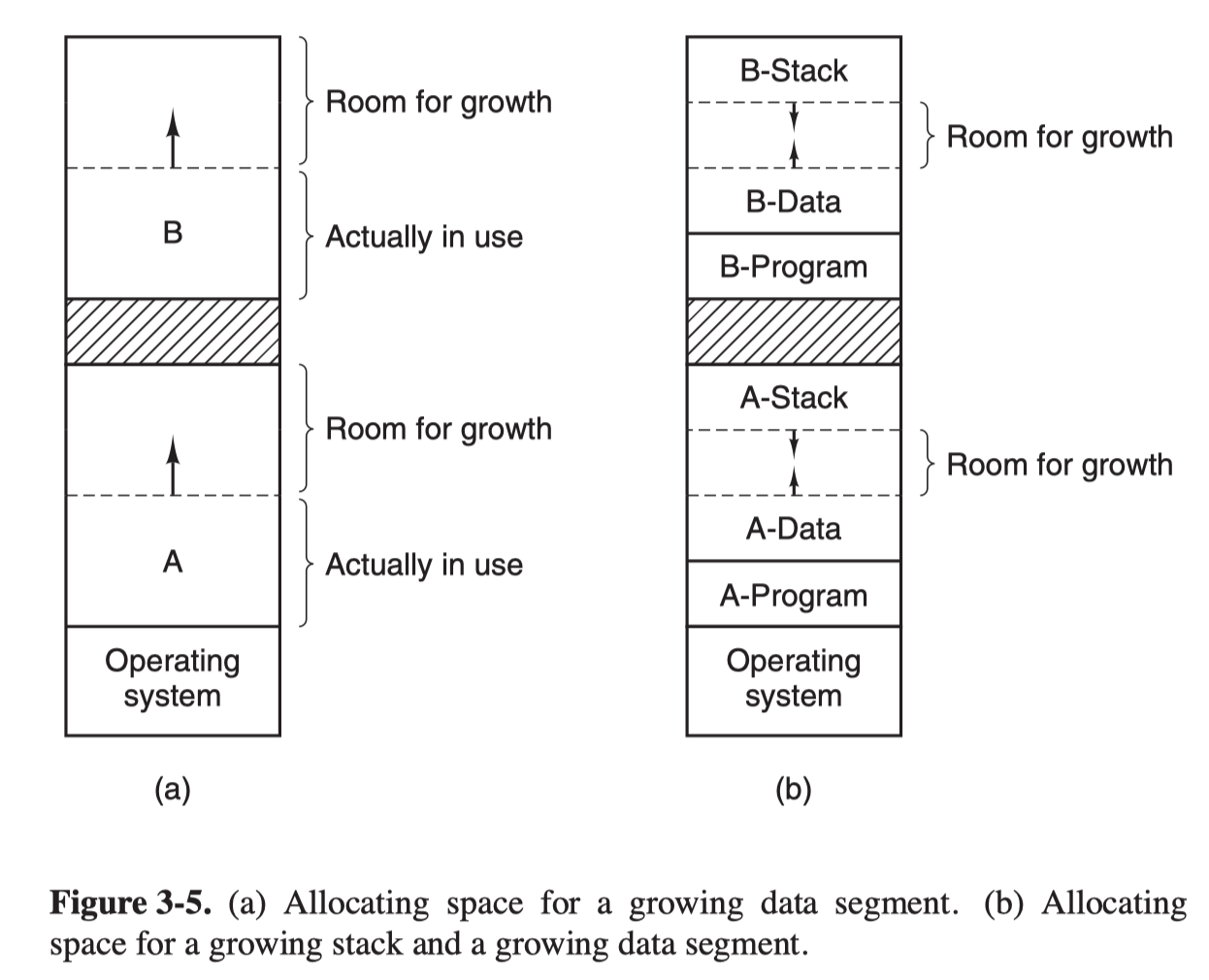
If a process tries a grow:
- if a hole is adjacent to the process, it can be allocated
- if not, it has to be moved to a bigger hole, or one or more processes have to be swapped out to create a larger enough hole
- if it cannot grow in memory and the swap area on the disk is full, the process has to be suspended until there is enough memory
Since most processes tend to grow, it is a good idea to allocate a little extra memory.
Managing Free Memory
When memory is assigned dynamic, the operating system must manage it. There are two ways to keep track of memory usage: bitmaps and free lists.
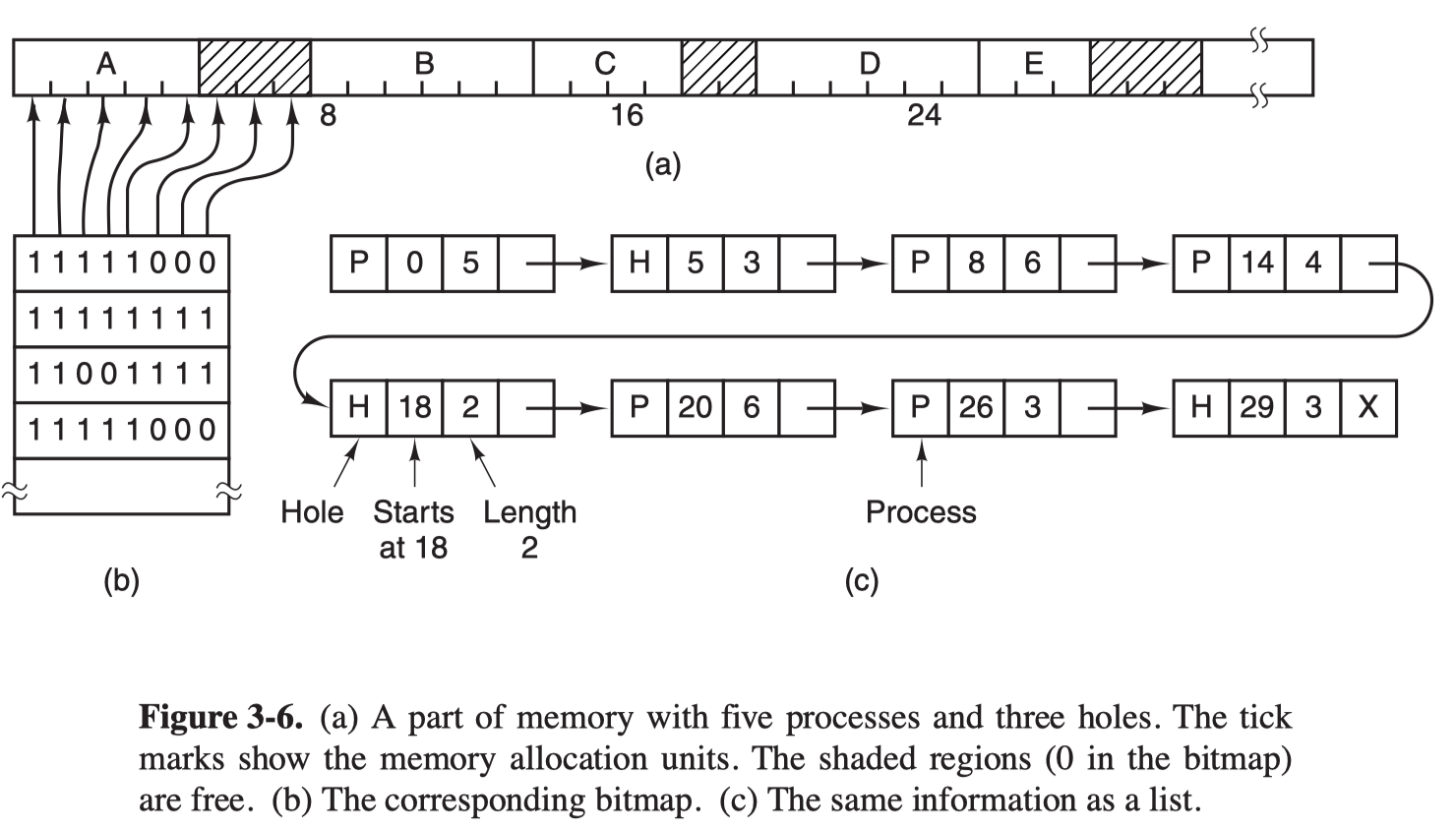
Memory Management with Bitmaps
With a bitmap, memory is divied into allocation units. Corresponding to each allocation unit is a bit in the bitmap, which is 0 if the unit is free and 1 if it is occupied.
The main problem is that when it needs to bring a $k$-unit process into memory, the memory manager must search the bitmap to find $k$ consecutive 0 bits in the map, which is quite slow.
Memory Management with Linked Lists
Another way is to maintain a linked list of allocated and free memory segements, where a segment either contains a process or is a hole.
It is more convenient to have the list as a double-linked list, which makes it easier to find the previous entry and see if a merge is possible.
Virtual Memory
The problem of programs larger than memory has been around since the beginning of computing, one method is known as virtual memory. The basic idea is that:
- Each program has its own address space, which is broken into chunks called pages
- Each page is a contiguous range of addresses
- Pages are mapped onto physical memory, but not all pages have to be in physical memory at the same time to run the program
Paging
Most virtual memory system use a technique called paging.
The program-generated addresses are called virtual addresses and form the virtual address space.
MMU (Memory Management Unit) maps the virtual addresses onto the physical addresses.
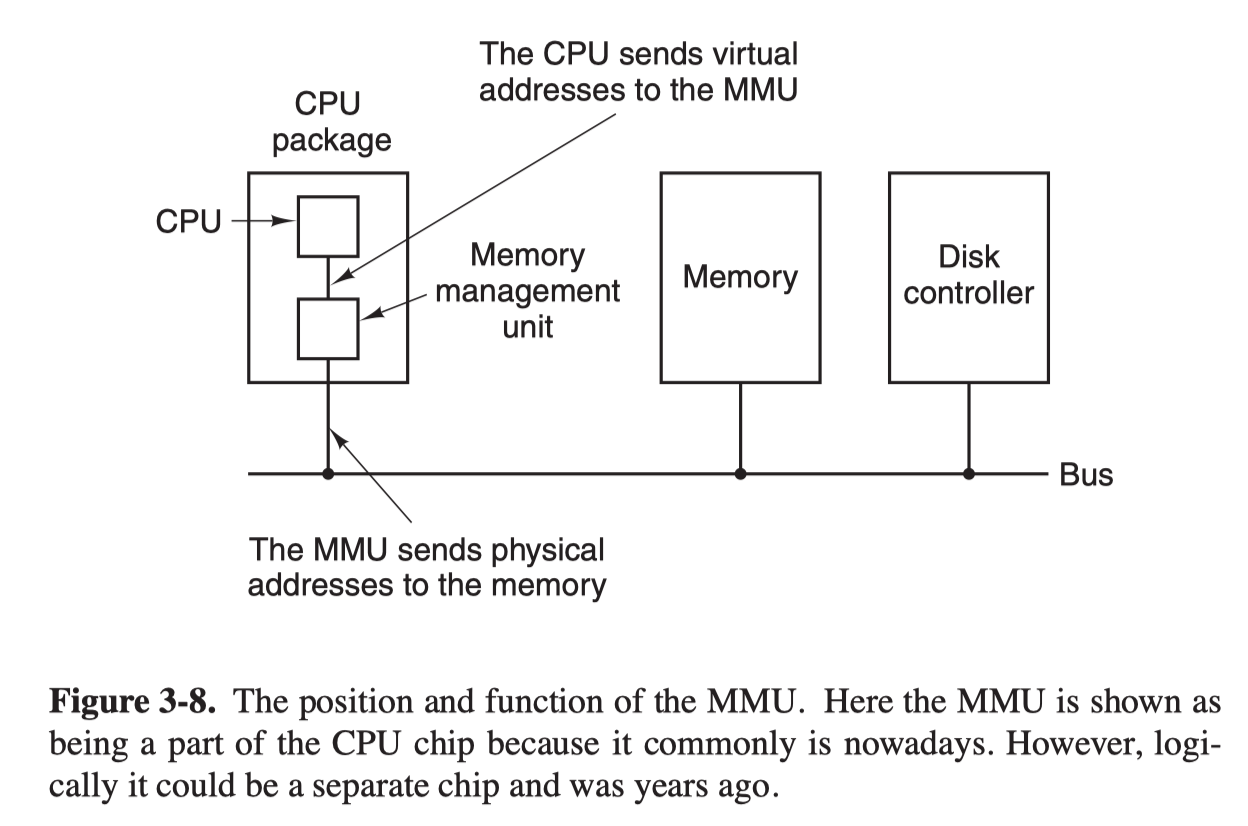
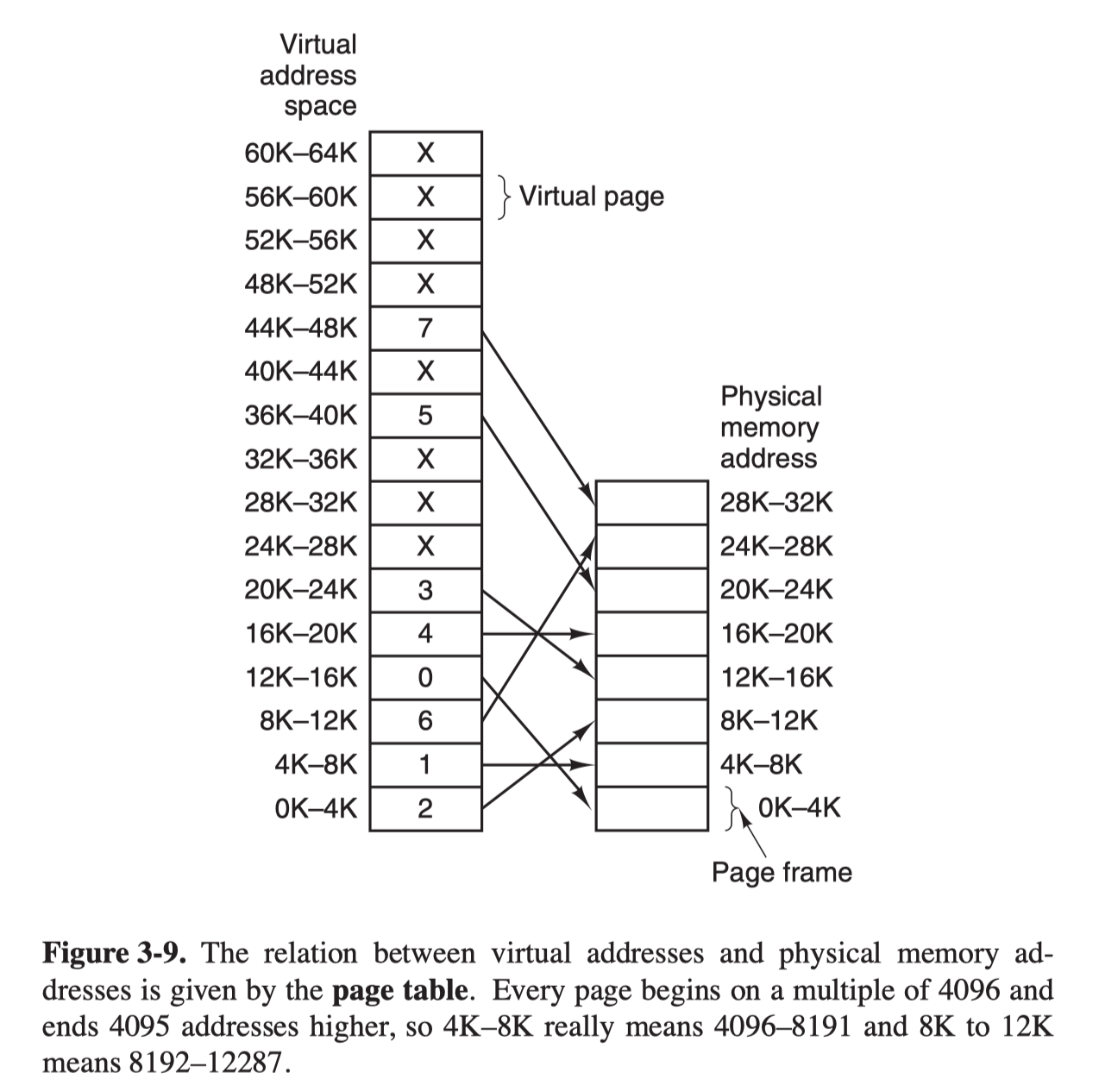
A simple mapping example is as follows.
- The virtual adddress space consists of fixed-size units called pages.
- The corresponding units in the physical memory are called frames.
- The pages and frames are generally the same size.
Page tables
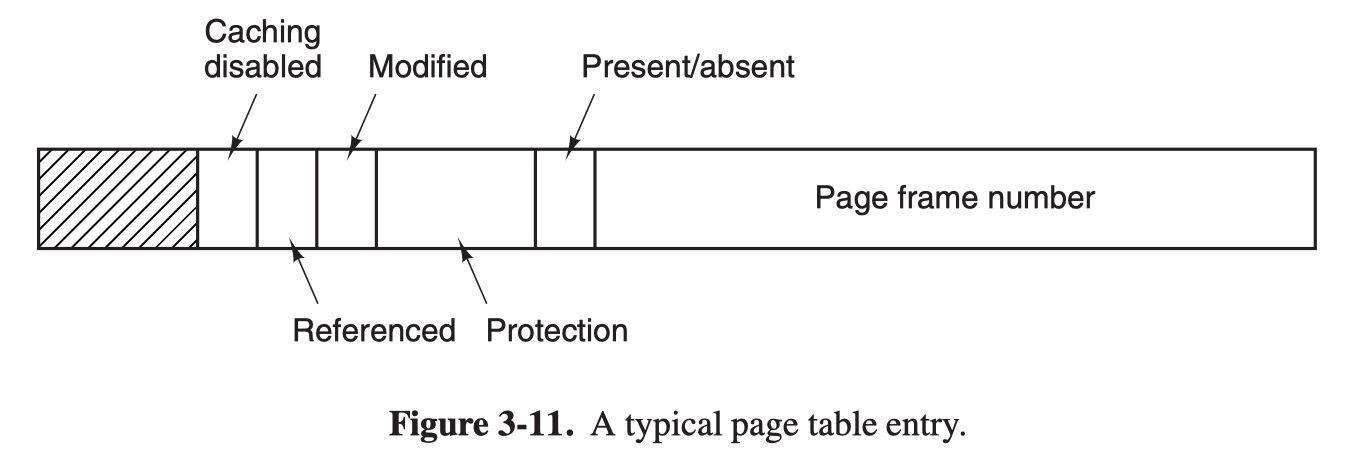
Structure of a page table entry
Let us go to the detials of a single page table entry.
Page frame number
Present/absent: 1 if the entry is valid cand can be used
Protection: ‘kernel’ + ‘w’
- if the kernel bit is set, only the kernel can translate this page
- if the writeprotected bit is set the page can only be read
Reference: set whenever a page is referenced, either for reading or for writing
Modified: set when a page is writtern to
Caching disabled
Speeding up Paging
In any paging system, two major issues must be faced:
- The mapping from virtual address to physical address must be fast
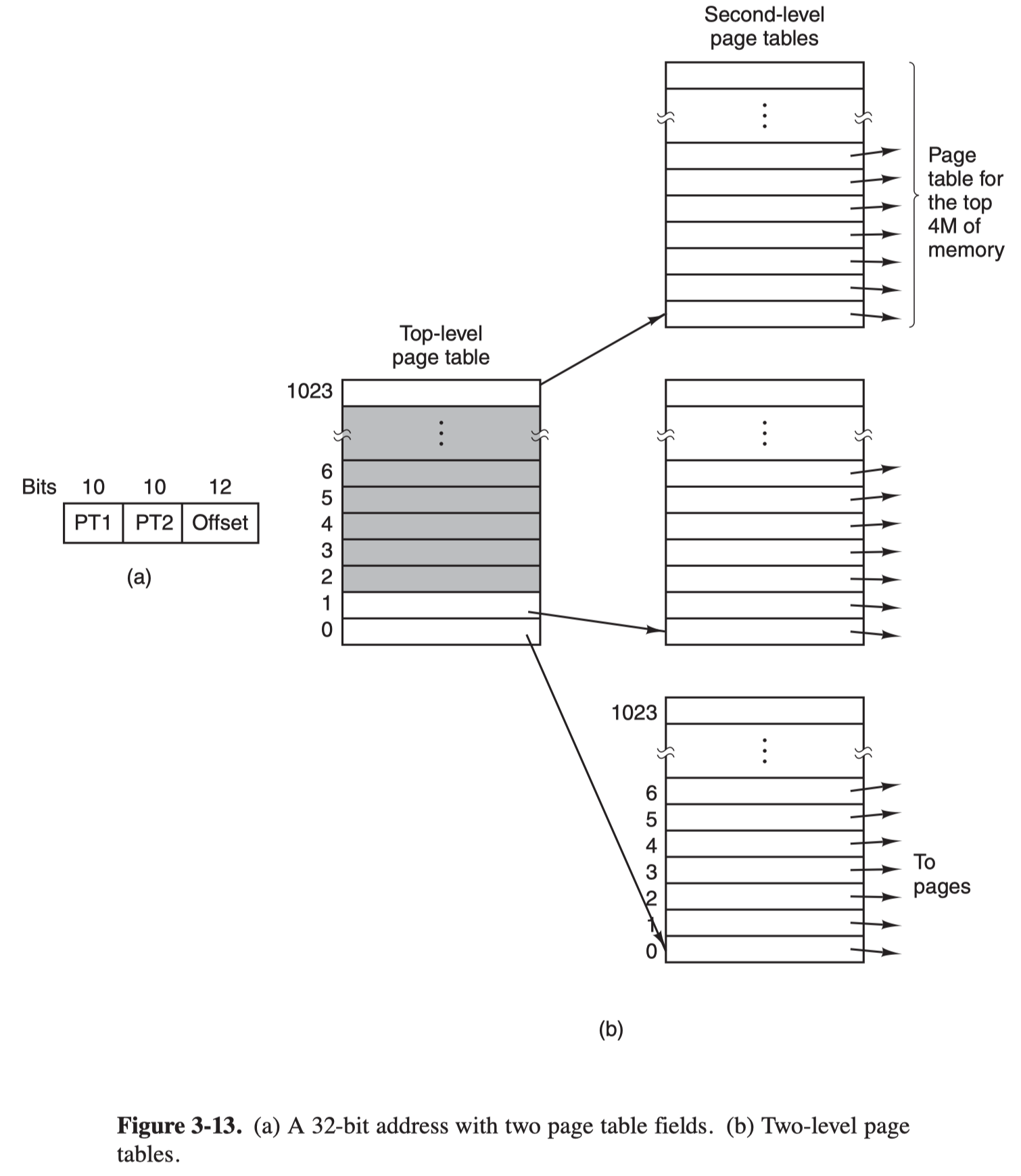
- If the virtual address space is large, the page table will be large
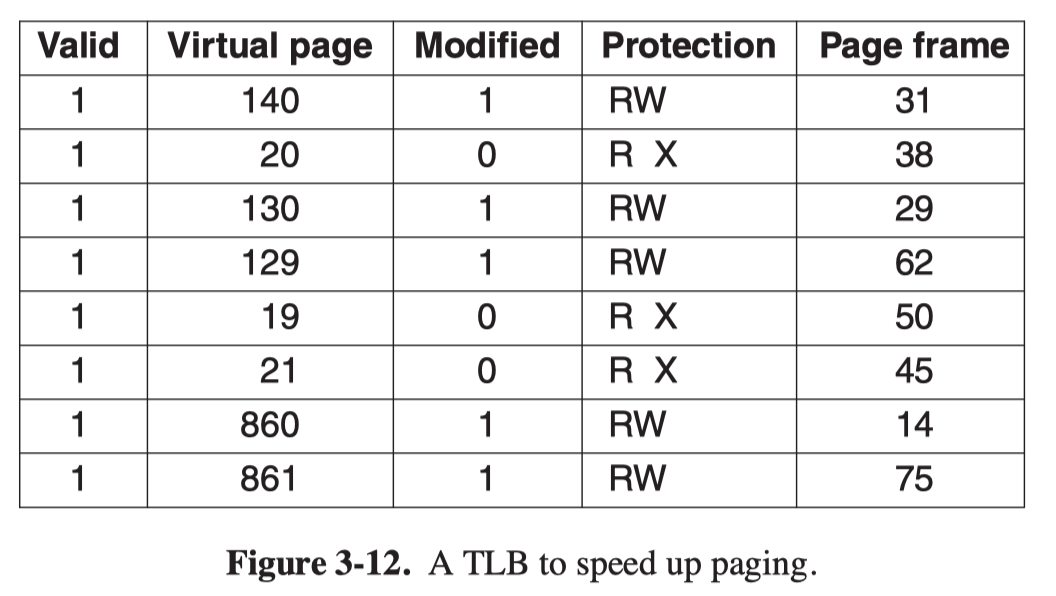
TLB (Translation Lookaside Buffer)
The solution for the first issue is to equip computers with a small hardware device for mapping virtual addresses to physical addresses without going through the page table. The device is called TLB, which is usually inside the MMU.
Multi-level Page Table
Shared Pages
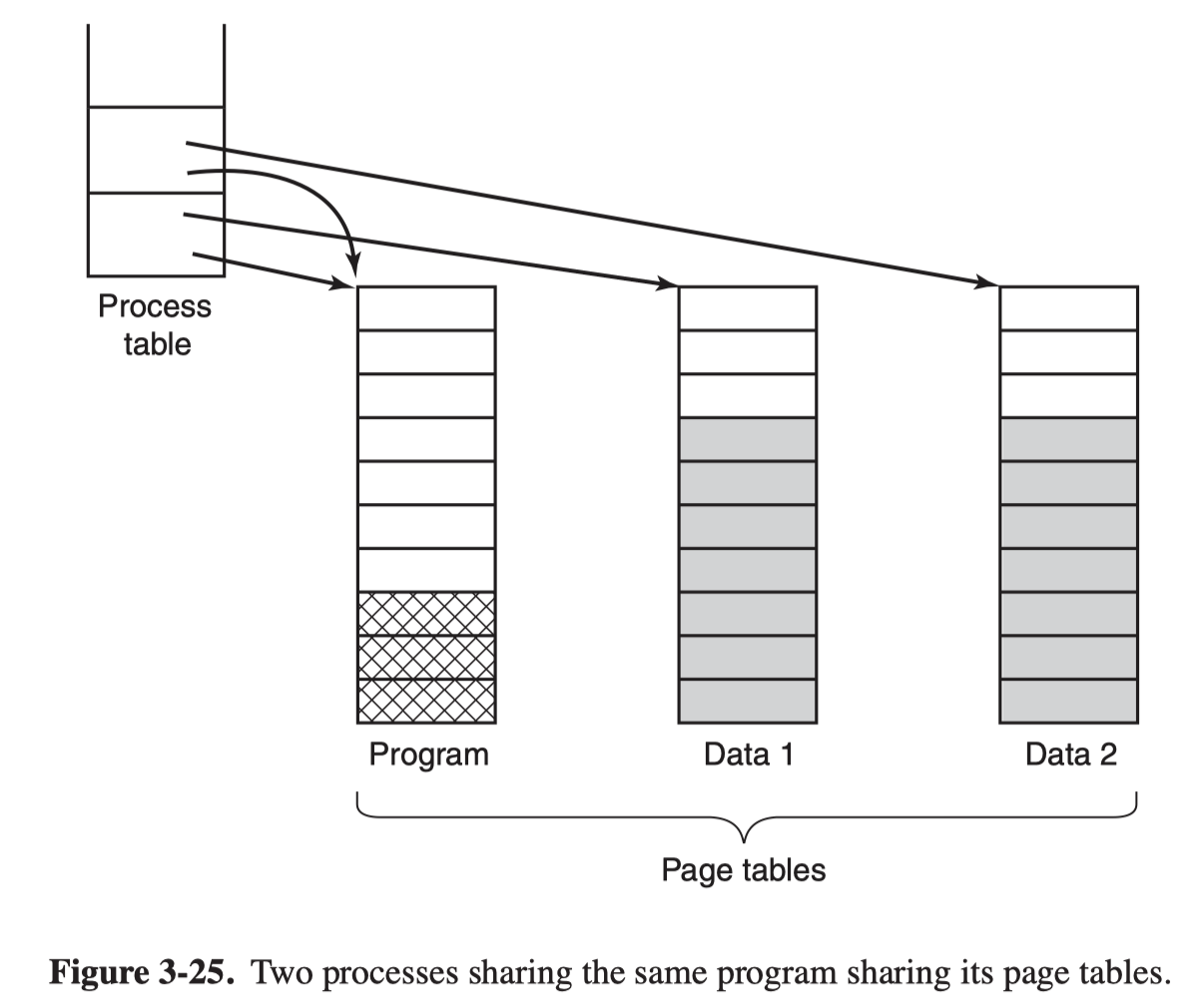
In UNIX, after the fork syscall, the parent and child are required to share both program text and data. It’s implemented as to give each process its own page table and have both of them point to the same set of page. However, all the data pages mapped into both processes as Read Only.
As soon as either a process updates a memory word, a copy is then made of the offending page so that each process now has its own private copy, both are now set Read/ Write.
Thie approach is call copy on write.
Page Replacement algorithms
Optimal Page Replacement Algorithm
Each page is labeled with the number of instructions that will be executed before the page is first referenced.
The page with the highest label should be removed
The FIFO Page Replacement Algorithm
- The operating system maintains a list of all pages currently in memory, with the most recent arrival at the tail and the least recent arrival at the head.
- On a page fault, the apge at the head is removed and the new page added to the tail of the list
The Second-Chance Page Replacement Algorithm
A simple modification of FIFO that inspects the R bit of the oldest page:
If it is 0, the page is replaced immediately.
If the R bit is 1,
- the bit is cleared,
- the page is put onto the end of the list of the pages
- the search continues
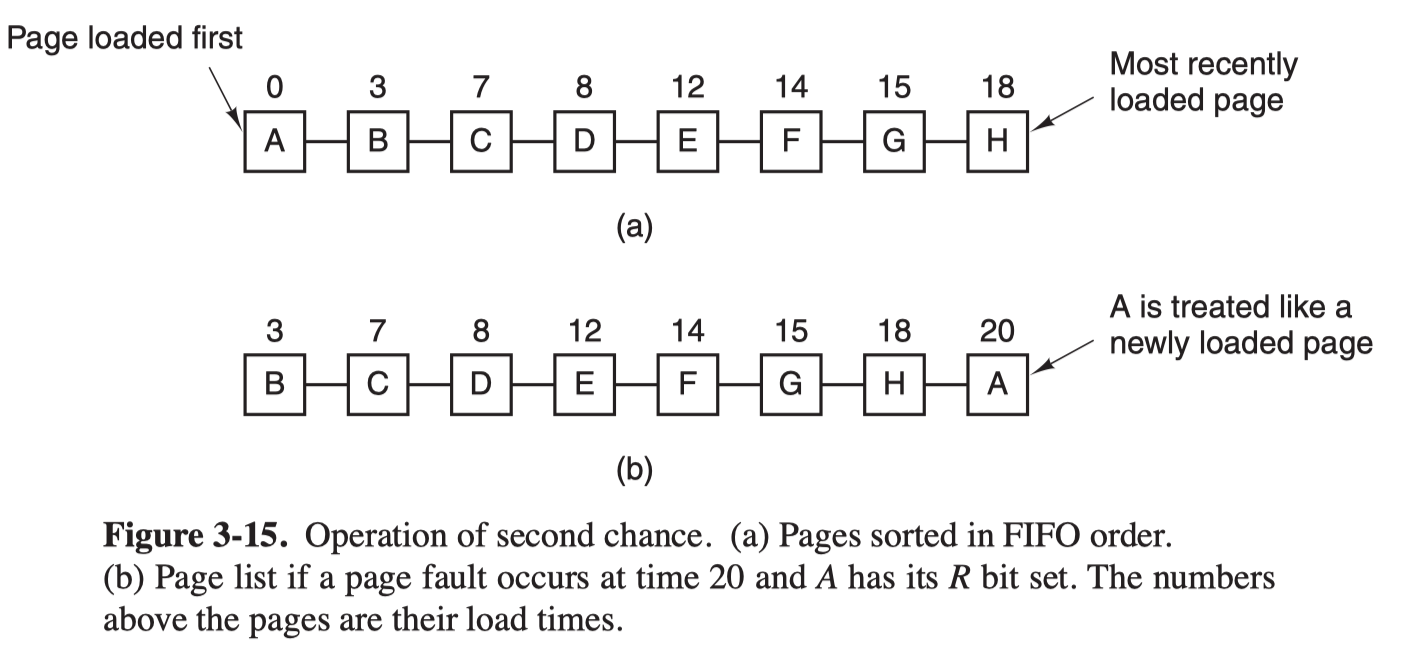
The Clock Page Replacement Policy
- Keep all the page frames on a circular list in the form of a clock
- The hand points to the oldest page
The Not Recently Used (NRU) Replacement Algorithm
Preidocially, the R bit is cleared
When a page fault occurs, the opearting system inspects all the pages and divides them into four categories based on current values of their R and M bits
- Class 0: not referenced, not modified.
- Class 1: not referenced, modified.
- Class 2: referenced, not modified.
- Class 3: referenced, modified.
The NRU (Not Recently Used) algorithm removes a page at random from the lowest-numbered nonempty class.
The Least Recently Used (LRU) Page Replacement Algorithm
When a page fault occurs, throw out the page that has been unused for the longest time.
Hardware Implementation
Equipping the hardware with a 64-bit counter, C, that is automatically incremented after each instruction.
Each page table entry must also have a field large enough to contain the counter.
After each memory reference, the current value of C is stored in the page table entry for the page just referenced.
When a page fault occurs, the operating system examines all the counters in the page table to find the lowest one.
Software Implementation
NFU (Not Frequently Used) Algorithm
It requires a software counter associated with each page, initially zero.
At each clock interrupt, the operating system scans all the pages in memory.
- For each page, the R bit, which is 0 or 1, is added to the counter.
When a page fault occurs, the page with the lowest counter is chosen for replacement.
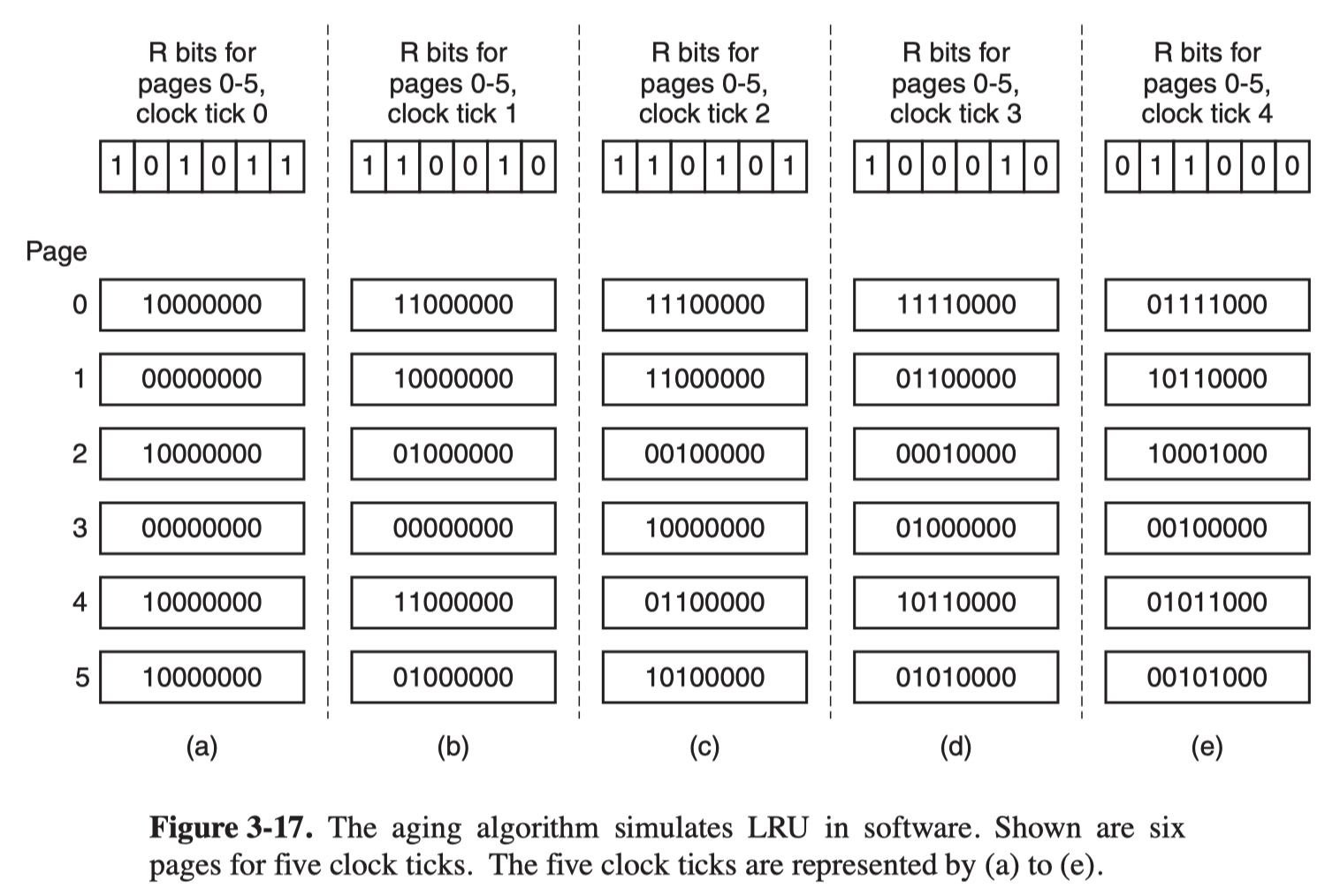
Aging Algorithm
It modifies NFU in two parts:
- the counters are each shifted right 1 bit before the R bit is added in.
- the R bit is added to the leftmost rather than the rightmost bit.
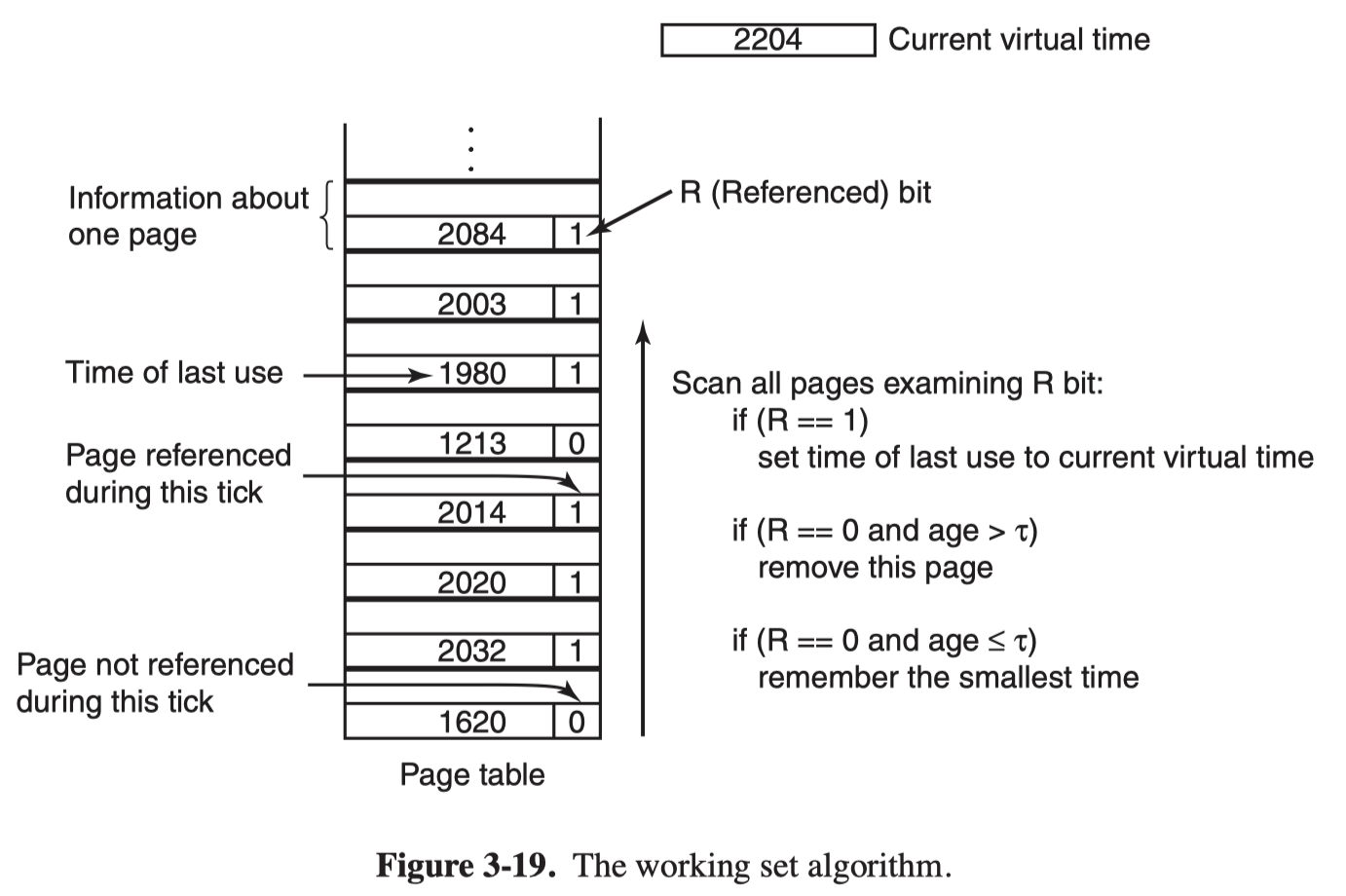
The Working Set Page Replacement Algorithm
The set of pages that a process is currently using is its working set. A program causing page faults every few instructions is said to be thrashing.
In a multiprogramming system, processes are often moved to disk. The question arises of what to do when a process is brought back in again.
Many paging systems try to keep track of each process’ working set and make sure that it is in memory before letting the process run. This approach is called the working set model. Loading the pages before letting processes run is also called prepaging.

The algorithm works as follows:
- Clear the reference bit periodically
- On every page fault, scan the page table and examine the R bit
- if it is 1, the current virtual time is written into the Time of last use field in the page table
- if R is 0, ts age (the current virtual time minus its Time of last use) is computed and compared to $\tau$. If the age is greater than τ , the page is no longer in the working set and the new page replaces it.
- The scan continues updating the remaining entries.
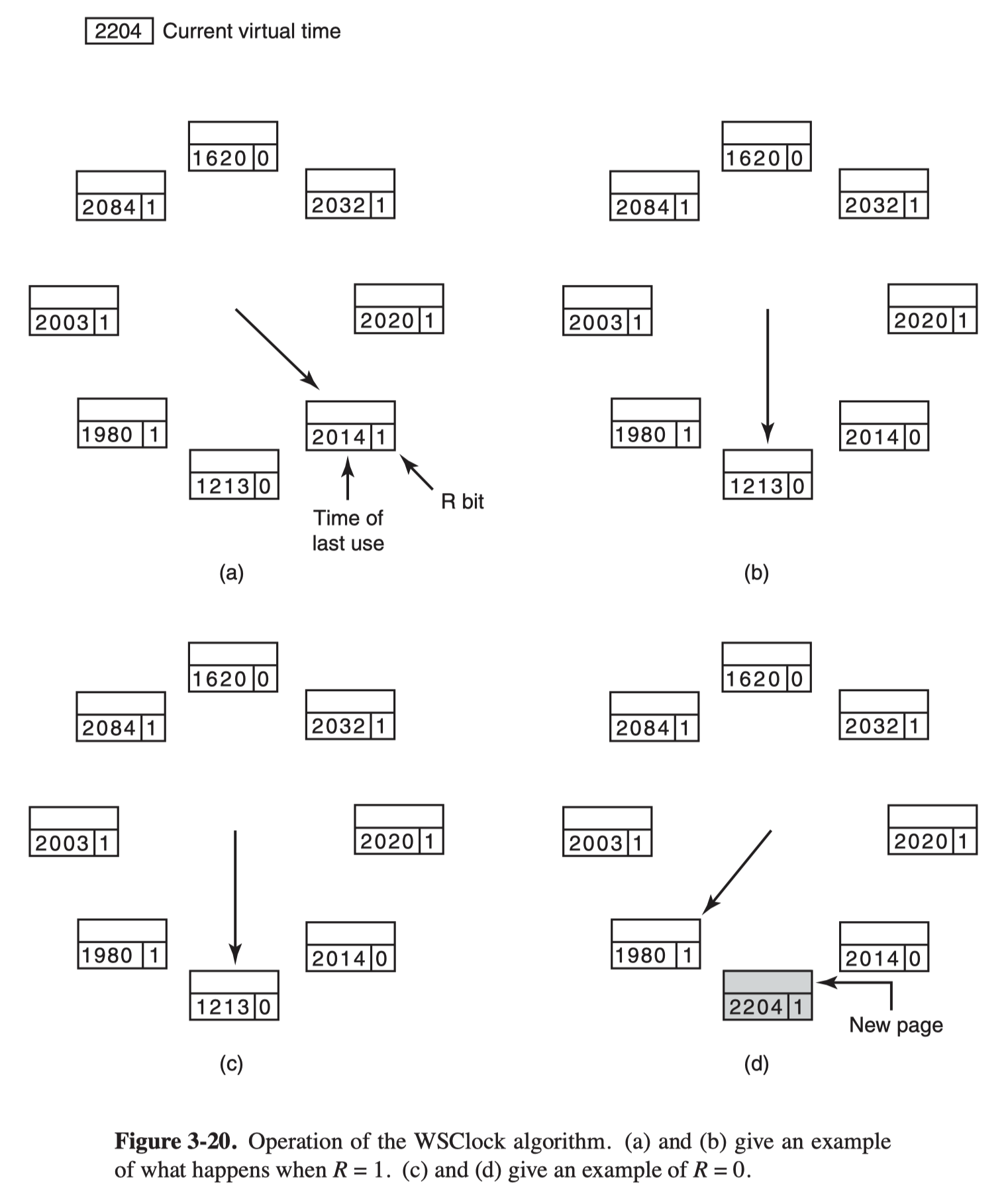
The WSClock Page Replacement Algorithm
- The data structure needed is a circular list of page frames, as in the clock algorithm
- Each entry contains the Time of last use field from the basic working set algorithm, as well as the R bit (shown) and the M bit (not shown).
- At each page fault the page pointed to by the hand is examined first.
- If the R bit is set to 1, the R bit is then set to 0, the hand advanced to the next page
- if the page pointed to has R = 0,
- If the age is greater than τ and the page is clean, the page frame is simply claimed and the new page put there
- if the page is dirty, the write to disk is scheduled, but the hand is advanced and the algorithm continues with the next page.
DESIGN ISSUES FOR PAGING SYSTEMS
Local versus Global Allocation Policies
If a global algorithm is used, the system must continually decide how many page frames to assign to each process.
- One way is to periodically determine the number of running processes and allocate each process an equal share.
- The other way is to start each process up with some number of pages proportional to the process’ size, but the allocation has to be updated dynamically as the processes run.
- One way to manage the allocation is to use the PFF (Page Fault Frequency) algorithm, It tells when to increase or decrease a process’ page allocation.
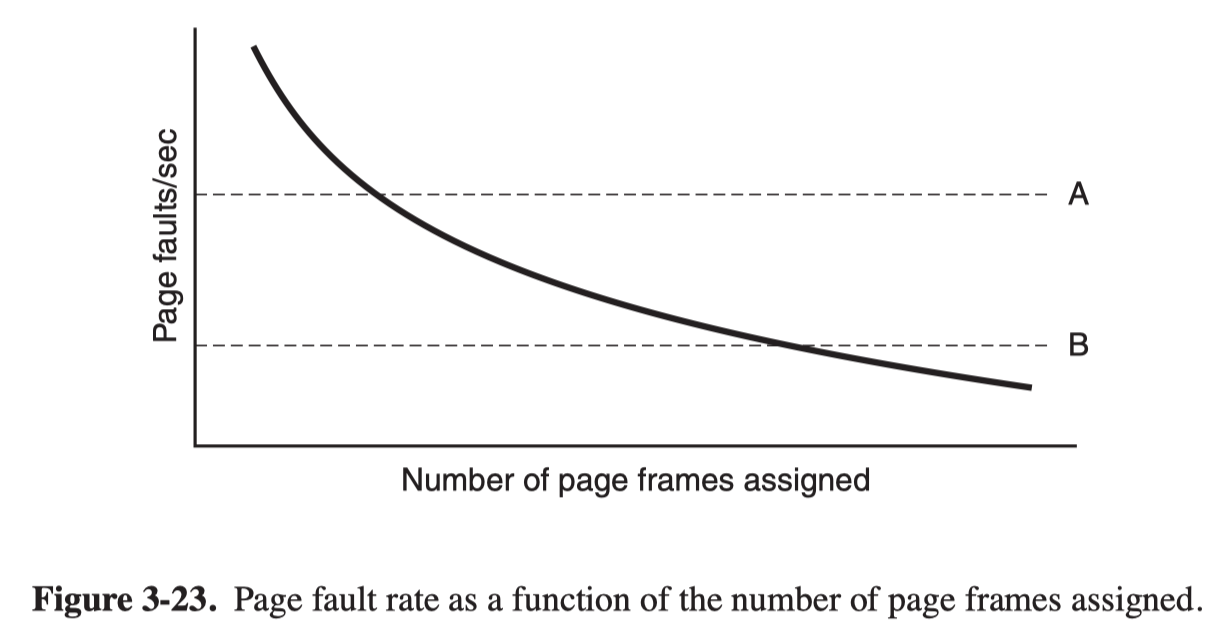
The dashed line marked A corresponds to a page fault rate that is unacceptably high, so the faulting process is given more page frames to reduce the fault rate. The dashed line marked B corresponds to a page fault rate so low that we can assume the process has too much memory. In this case, page frames may be taken away from it. Thus, PFF tries to keep the paging rate for each process within acceptable bounds.